http://blog.teamleadnet.com/2012/07/quick-select-algorithm-find-kth-element.html
Quick select algorithm - find the Kth element in a list in linear time
Quick select algorithm (Hoare's selection algorithm) – select the Kth element or
the first K element
from a list in linear time
Working with large datasets is always painful, especially when it needs to be displayed in a ‘human readable’ format. It is a very frequent task to display only the largest, newest, most expensive etc. items. While sorting the whole dataset definitely gives a correct result, it is much slower than it needs to be – it needs at least O(n*log(n)) time and an it often uses recursion for the sorting, so in practice it can be quite slow.
The quick select algorithm can get the top K element from a list of N items in linear time, O(n), with a very reasonable multiplication factor. The quick select does not use recursion so the performance is great for even large datasets.
Algorithm
The idea of the quick select is quite simple: just like with quicksort, select a random element from the list, and place every item that is smaller to the first half of the array, and every element that is equal to or greater than the pivot, in the second half (the ‘half’ is not entirely correct, as it is possible that the result will not be exactly ‘half’).
So a step would look like this:
Arr = [5 1 4 3 2]
Pivot = [4]
Steps:
swap [5] and [2] as 5
>
=4 and 2
<
[2 1 4 3 5]
swap [4] and [3] as 4
>
=4 and 3
<
4
[2 1 3 4 5]
When we finish with the first iteration, we know the followings:
All elements
<
4 are on the left of 4
All elements
>
=4 are on the right of 4 \(including the 4 itself\)
So, if we are looking for the first 3 elements, we can stop, we found them. If we are looking for the 3rd element, we need more iteration, but we know we must look for it in the first half of the array hence we can ignore the rest:
Arr = \[2 1 3 …\]
Pivot = \[1\]
Steps:
swap \[2\] and \[1\] as 2
>
=2 and 1
<
2
\[1 2 3 …\]
When we finish this iteration, we know the followings:
All elements
<
1 are on the left of 1 (none in this case)
All elements
>
=1 are on the right of 1 (including the 1 itself)
If we were looking for the 1st element, we are done, [1] is the first. However, we know the 3rd element must be right from the [1] and left from [4]:
Arr = […2 3…]
Pivot= [2]
…
Just like with binary search, we keep dropping a segment from the array as we are getting closer to the solution. On average, we halve the search space so it gives us a geometrical series of operations. In the first step, we work with all the items, which is N. The next iteration works only with roughly the half of the array, which is N/2 and so on:
Work = n + n/2 + n/4 + …
To sum it all up, we can use the similarity rule:
Work/2 = n/2 + n/4 + n/8 + …
Hence:
Work – \(Work/2\) = n
Work/2 = n
Work = 2n
Work = O\(n\)
Running benchmark
So it is quite clear that this algorithm runs in linear time. The quick selection algorithm Java code would look like this:
As the algorithm is nice and linear without recursion or complex branches, we expect a very good running time.
To test is, I’ve run the quick select against different array sizes between 1 and 20 million and checked the relative running times (the graph shows many runs summed on the arrays as a single run was too quick to measure precisely):
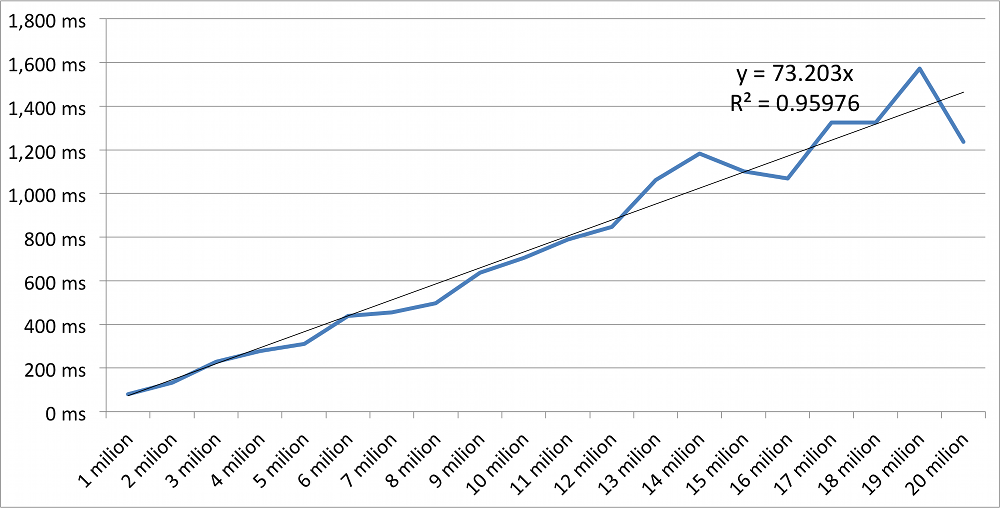
The graph supports the idea that it is really linear, so that’s good. But how about sorting the array? The following graph shows the sorting and quick select in relative time compared to each other:

It is interesting to note that O(n*log(n)) is almost linear (log(1million)~=20, log(20million)~=24) but still much slower than our quick select implementation.
Quick select than sorting or heap
As sorting the whole dataset is quite slow, it makes sense to select the top K items and sort only that few ‘top’ elements giving the impression to the user as the whole dataset was sorted as she pages through the result set. This will give a running time of O(k*log(k) + n) as opposed to O(n*log(n)) which is much faster if K is reasonably small (few hundreds for example).
An other approach would be to work with a heap and keep popping the smallest number while putting back a larger as we are receiving the N numbers as a stream. This would work with O(n*log(K)) running time as the heap holds K elements so the height is log(K) while we test N numbers in total, although it’s expected running time is larger than the quick select and sort combination.
public static int selectKth(int[] arr, int k) {
if (arr == null || arr.length <= k)
throw new Error();
int from = 0, to = arr.length - 1;
// if from == to we reached the kth element
while (from < to) {
int r = from, w = to;
int mid = arr[(r + w) / 2];
// stop if the reader and writer meets
while (r < w) {
if (arr[r] >= mid) { // put the large values at the end
int tmp = arr[w];
arr[w] = arr[r];
arr[r] = tmp;
w--;
} else { // the value is smaller than the pivot, skip
r++;
}
}
// if we stepped up (r++) we need to step one down
if (arr[r] > mid)
r--;
// the r pointer is on the end of the first k elements
if (k <= r) {
to = r;
} else {
from = r + 1;
}
}
return arr[k];
}--;